整体背景
周一(4月14日)在Twitter上看到katon发了一个帖子,介绍Github上开源的生成GPT-4o 精美图片的Prompt目录,最近GPT4o绘画很火,尤其是Ghibli风格大火。仓库中收集的case效果都非常赞,加上X上的几个大佬一推荐,这个仓库上线当天Star数量就超过500了,刚去看了下最新Star已经到3.8K了。
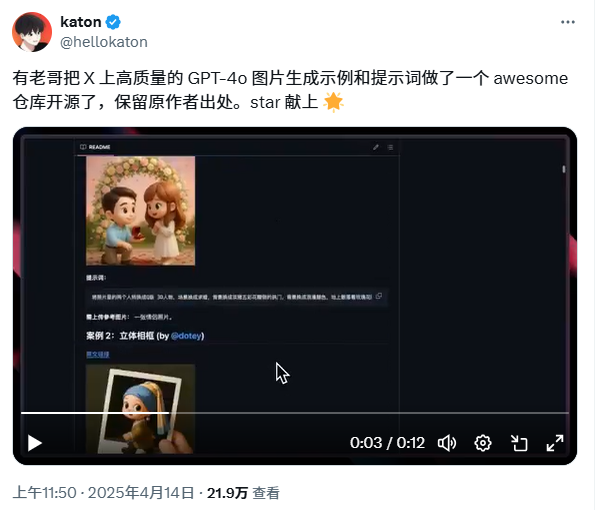
浏览X原贴下面,其中Shao | 少蒙 提到如果有个平台目录就好了,觉得是个不错的需求,于是当天晚上手糊了一个online在线版。
BTW,为了在全球加速访问,尤其是在国内免域名备案与CDN加速,我已经将网站部署到 https://prompt.laomeinote.com/ 了,欢迎大家访问试用。
此后白天上班晚上加新功能,共计5天,差不多每天2小时,基本完成一个可用的Online在线版本,也开源在github上了:awesome-gpt4o-images-prompt-online
包括基本功能:
- 📸 精选案例展示
- 高质量的 GPT-4 Vision 创作案例
- 包含详细的提示词说明
- 支持查看原始创作链接
- 🔍 强大的筛选功能
- 标签分类筛选
- 按照作者筛选
- 关键词搜索
- 💡 便捷的提示词管理
- 代码框式提示词展示
- 一键复制功能
- 优雅的复制成功提示
- 🎨 精美的用户界面
- 响应式卡片布局
- 深色模式支持
- 流畅的动画效果
- 👥 用户系统
- 多用户登录支持
- 永久收藏保留
- 点赞和收藏同步
- 🌐 多语言支持
- 中英文切换
- 完整的国际化体验
🔨️ 技术栈
- 前端框架: Next.js
- 样式方案: Tailwind CSS
- 动画效果: Framer Motion
- 图标: React Icons
- 图片优化: Next.js Image
- 类型检查: TypeScript
- 认证鉴权: Supabase Auth
- 数据存储: Supabase PostgreSQL
- 部署方式:Vercel / Cloudflare Pages (支持全球/含国内免域名备案加速)
好了,上面是整体背景,接下来开始总结使用Cursor和Windsurf开发这款小APP历程。
技能介绍
在总结这次AI开发之前先介绍下作者技能情况:
作者正经工作是面向私有云场景提供上云解决方案,做过三年K8s/Docker相关工作,平时写点小Python/Shell脚本,会一点SQL的CURD操作,会一点点HTML/CSS/JS写点巨丑无比的前端。简而言之,非开发岗位,很少Coding。
Cursor/Windsurf/Cline 大火的时候,分别体验过,可能是自己使用Prompt提示不对,可能是当时AI模型还不成熟,尝试写过几个小应用,都不满意,最后不了了之。
也尝试过直接使用ChatGPT和Claude写过小应用,为此被封了几个号,汗~~~
这次趁机重新开通了Cursor / Windsurf账号糊了这个APP,算是一次AI编程的祛魅过程吧。
开发过程
- 获取素材
由于jamez-bondosy 已经总结好了Markdown格式的案例库,所以起步很简单,克隆Github仓库https://github.com/jamez-bondos/awesome-gpt4o-images, 主要是获取的这个库的Readme.md与对应的图片文件。
- 创建工程
在本地创建一个目录,就取名awesome-gtp4o-images-prompt-online,添加一个github-docs目录,把仓库中的Readme.md和图片文件放到这个目录,主要是为了给Cursor参考,然后用Cursor打开目录开始写Prompt了,使用Claude-sonnect-3.7,Agent模式。写的提示词很简单,告诉他:
github-docs/doc/ref.md 中收集了很多GTP4o Image Prompt,用于给AI创建精美的图片,我需要把这个文档中的43个Case写成一个Online版本的目录,支持按照作者进行筛选,支持对这些Case自动分类,支持首页搜索。使用Nextjs + Tailwind CSS进行开发。
然后Cursor(Claude)就开始像个勤劳的小蜜蜂开始工作了,帮我把整个工程都创建好了。是的,我都没有使用Nextjs脚手架创建工程。
- 不断优化
由于第一版功能简单,一路顺畅几乎没有报错,直接就完成了。后面都是添加一些小功能,稍微提示一下就行,但是需求要列清楚,比如使用提示词:
(1)需要SEO友好。
(2)修改为移动端自适应。
(3)支持多语言国际化。
(4)支持Light/Dark主题切换。
确实只加了这些小的描述,勤劳的小蜜蜂就吭哧吭哧完成了大部分功能,当然期间也有出错,把报错信息贴给Cursor就行了。
- Gemini上马
前面功能简单,没有什么挑战,唯一不够满意的是,原始文档中有43个Case,Cursor帮我生成的数据里只有前面10个Case,让它生成更多案例的时候就报错,或者处理很久。估计Cursor报错是因为上下文数量有限导致的。
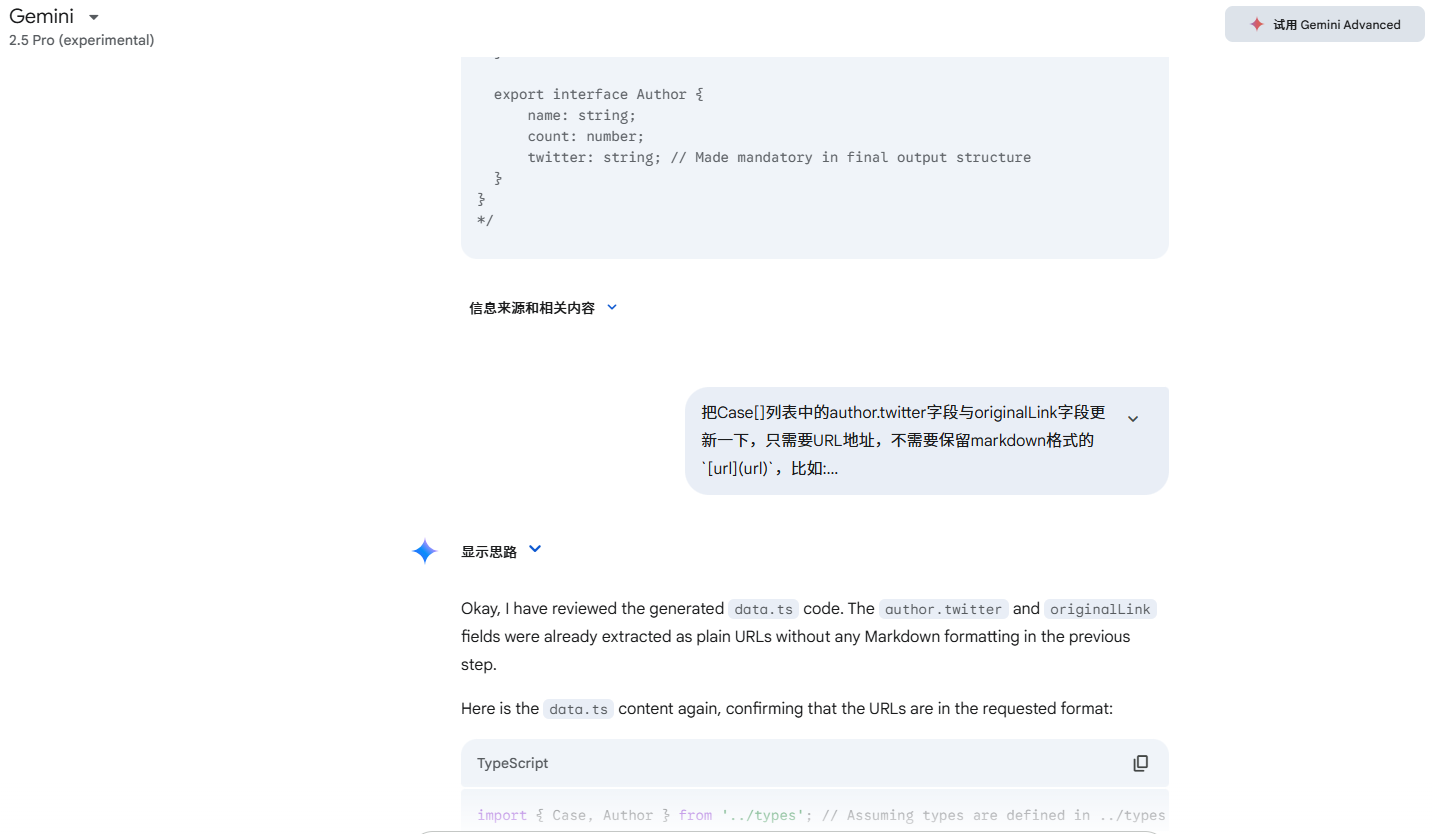
自己分析了一下Cursor要处理的Case其实就是把Markdown中的数据整理成Nextjs识别的Json格式数据,需要上下文处理的场景丢给号称有1M上下文的Gemini不是更好,不幸的是,Gemini收到Markdown文件也罢工了,不知道什么原因,不过好在它支持上传整个文件夹,所以我把参考的文件夹上传上去,让Gemini提取数据了。丢给Gemini的Prompt如下:
识别文件夹中的ref.md文件,然后输出一个data.ts文件,其内容需要如下:
其中export const cases: Case[]是一个列表,对应附件中的43个case,每个case需要有id, title, author, originalLink,prompt,requiresReferenceImage,tags.
(1)id就是case序号
(2)Title就是case的title,默认为中文,请提取中文内容,然后翻译为英文,分别赋值给zh,和en.
(3)author就是case的title中by后面的作者,提取它的name和链接地址。
(4)originalLink对应case中的原文链接。
(5)image对应的链接就是case中的的src地址,但是对应为根目录的地址,即`/examples/xxx`
(6)prompt对应case中的提示词,默认为中文,请提取中文内容,然后翻译为英文,分别赋值给zh,和en。
(7)根据Title和Prompt你想象一下可以提取哪些tag,也需要设置为中文和英文的,分别赋值给zh,和en,做多提取3个Tag,最少1个。
另外,export const authors也是一个列表,需要把Case中所涉及到的所有Author提取出来。 如下示例:
```ts
export const cases: Case[] = [
{
id: "1",
title: {
zh: "立体相框",
en: "3D Photo Frame"
},
author: {
name: "dotey",
twitter: "https://x.com/dotey"
},
originalLink: "https://x.com/dotey/status/1908238003169903060",
image: "/examples/example_polaroid_breakout.png",
prompt: {
zh: "将场景中的角色转化为3D Q版风格,放在一张拍立得照片上,相纸被一只手拿着,照片中的角色正从拍立得照片中走出,呈现出突破二维相片边框、进入二维现实空间的视觉效果。",
en: "Transform the character in the scene into a 3D chibi style, placed on a Polaroid photo being held by a hand. The character is stepping out of the Polaroid photo, creating a visual effect of breaking through the 2D photo frame and entering the 2D real space."
},
requiresReferenceImage: true,
tags: {
zh: ["3D", "Q版", "创意"],
en: ["3D", "Chibi", "Creative"]
}
},
];
export const authors = [
{ name: 'balconychy', count: 7, twitter: 'https://x.com/balconychy' },
{ name: 'dotey', count: 15, twitter: 'https://x.com/dotey' },
{ name: 'AnimeAI', count: 2, twitter: 'https://x.com/AnimeAI' },
{ name: 'ZHO_ZHO_ZHO', count: 9, twitter: 'https://x.com/ZHO_ZHO_ZHO' },
{ name: '0xdlk', count: 1, twitter: 'https://x.com/0xdlk' },
{ name: 'richardchang', count: 1, twitter: 'https://x.com/richardchang' },
{ name: 'gizakdag', count: 1, twitter: 'https://x.com/gizakdag' },
{ name: 'op7418', count: 1, twitter: 'https://x.com/op7418' },
{ name: 'hellokaton', count: 1, twitter: 'https://x.com/hellokaton' }
];
```
Gemini很快处理好了,结果稍微按照要求调整一下就可以用了。
- Windsurf上马
本来Cursor工作的好好的,第三天我开始继续写代码之前,手贱了下载了一个最新版本的Cursor,因为看到0.49版本的Cursor可以协助写Cursor Rules,结果升级之后之前的历史会话打不开了,这下好了,之前的记忆全没了,需要重新调教AI了。想着既然重新开始,要不试试Windsurf,考虑到我的Windsurf是很早之前就订阅过,所以重新订阅只需10$/月,比Cursor便宜一倍。
调教开始:
第一回合:让它学习当前工程
查看这个项目的 @package.json 和 @README.md 文件以及项目中的其他文件分析一下这是个什么项目,写一个windsurf rule指导后续开发,需要风格一致。分析完了之后它开始贴心的写cursorrule了,奇怪的是没有写自己的rule,还是使用之前的cursorrule,不过我担心它对项目了解不深,所以继续让它学习下其他目录下的文件与内容避免它胡写乱写代码,造成冗余代码。
第二回合:指定目录给AI学习
@app/auth 和 @lib/auth 以及 @hooks 分别有什么作用,里面的文件分别怎么互相工作的问它这些目录的作用,学完了之后继续指定其他目录,直到你认为所有重要目录都已经喂了一遍给它。
第三回合:开始给AI指定规则了
好了,你已经基本完整的了解了这个项目架构与技术栈。请你总结一下project structure,以及对应技术实现方案,整理成windsurf规则。在此基础上我们继续完善用户中心的页面设计与逻辑,需要前后逻辑与风格一致。先完成windsurf规则的编写吧。好了,勤劳的小蜜蜂开始吭哧吭哧写规则了,略去不表。
第四回合:让它开始干活,但是现不要着急,出完方案先。
这点很重要,因为我还不是很信任它真的了解了整个项目,怕它乱来乱改代码,所以学习Cline的PLAN/ACT模式,也即:要求它先Plan规划出方案,再Act执行。如:
现在的Dashboard页面不好看,我重新设计了一个原型如截图,如果要修改成这个原型,需要怎么修改,改动的地方包括哪些,需要注意哪些?先告诉我你的想法,我同意了再修改。然后勤劳的小蜜蜂又开始吭哧吭哧出方案了,我觉得靠谱之后才开始更新了个初版。不过看起来Claude在写精美的样式上并不占优或者是我的提示词并没有描述清楚,最终也没达到我想要的效果。不得已,我上到V0找了个Case,让V0修改了一版,然后截图再丢给Windsurf,最终才逐步完成修改。这些也略去不表,大家清楚过程就好。
第X回合
再后面就是不断加新功能,不断问它方案,然后同意了再写代码的过程。后面逐步加了Supabase多用户登陆功能,加了支持用户收藏/点赞写入数据到Supabase数据库功能了。
由于是PLAN/ACT模式,应该是更耗费Credit,如果对于已经清晰的问题和方案可以让它直接修改节省Credit。
当然在持续迭代过程中,持续打结是必不可少的。也就是说,新功能完成/问题解决后,通过Git Commit提交,避免下次AI把代码改乱了都不知道回退到哪个时间点去。

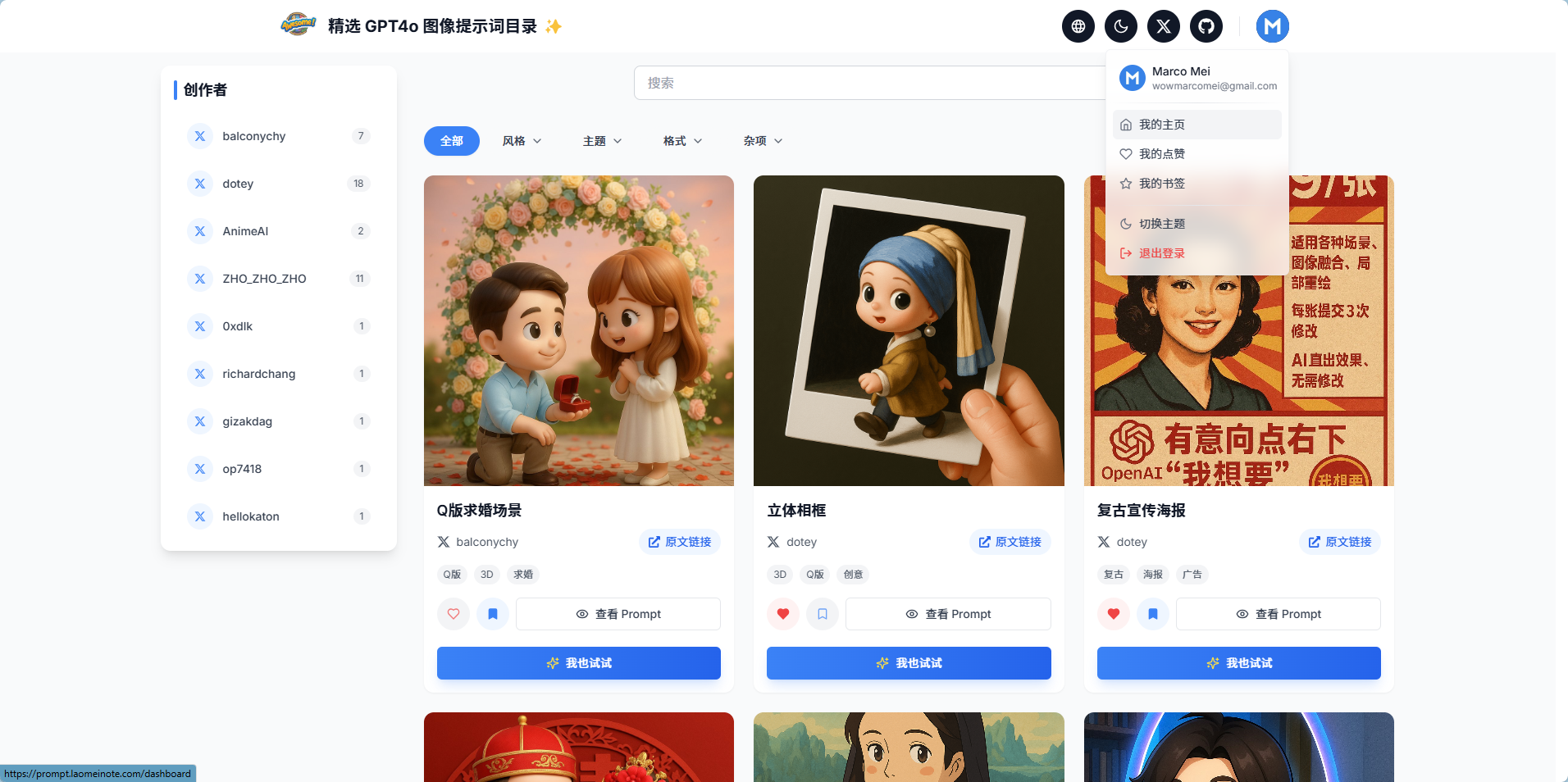
最后本地调试的差不多了,看看成果:
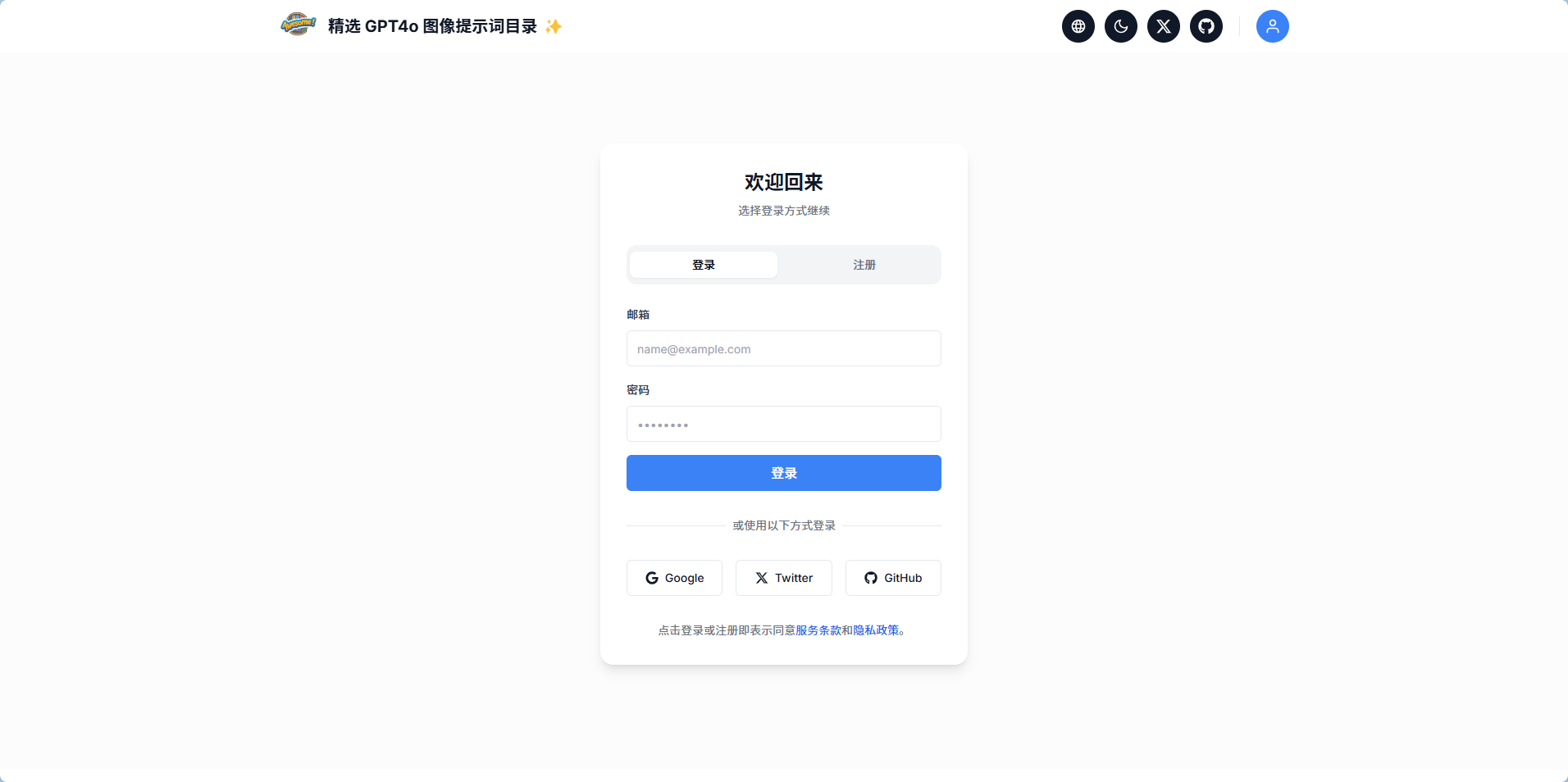
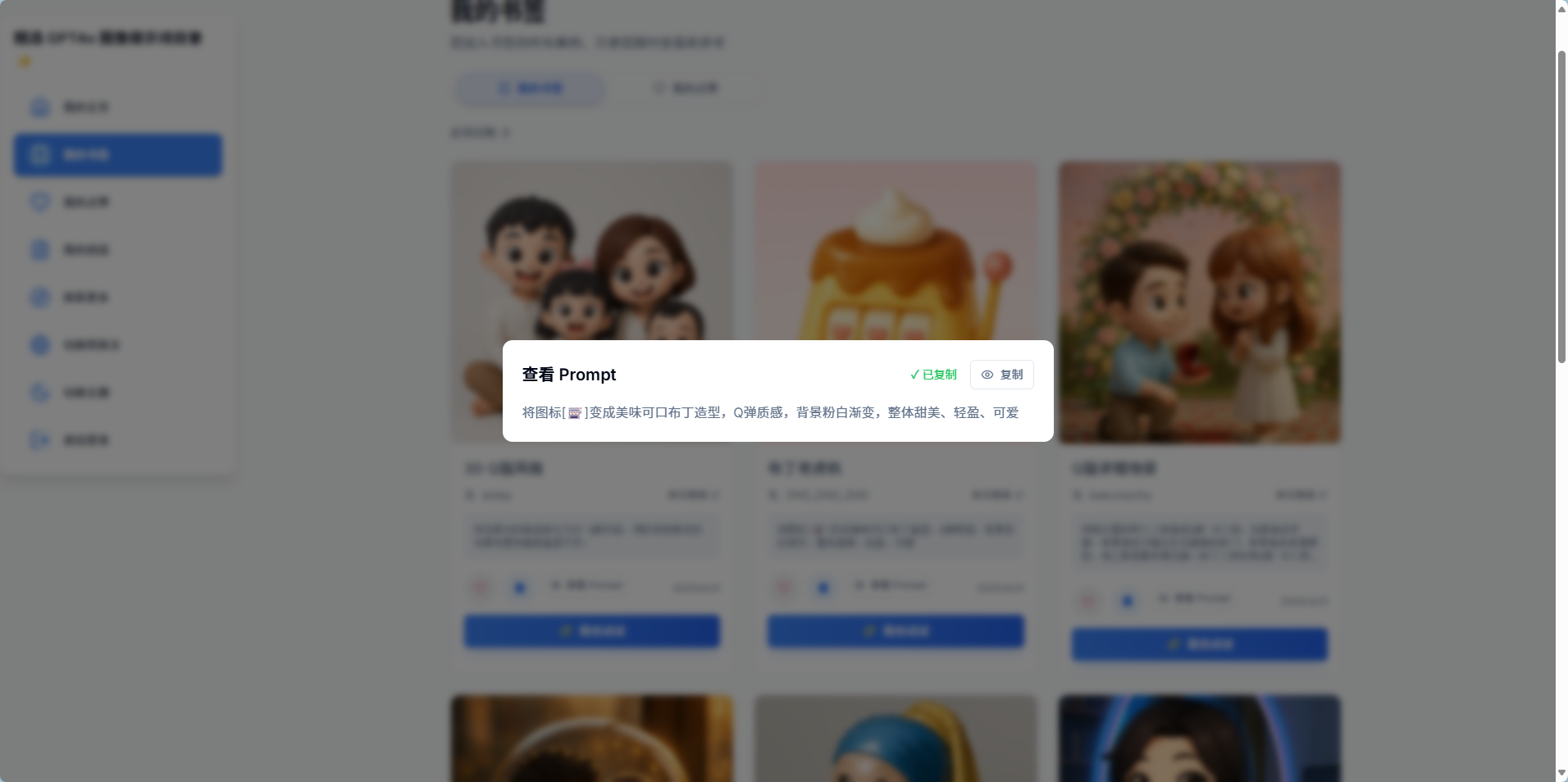
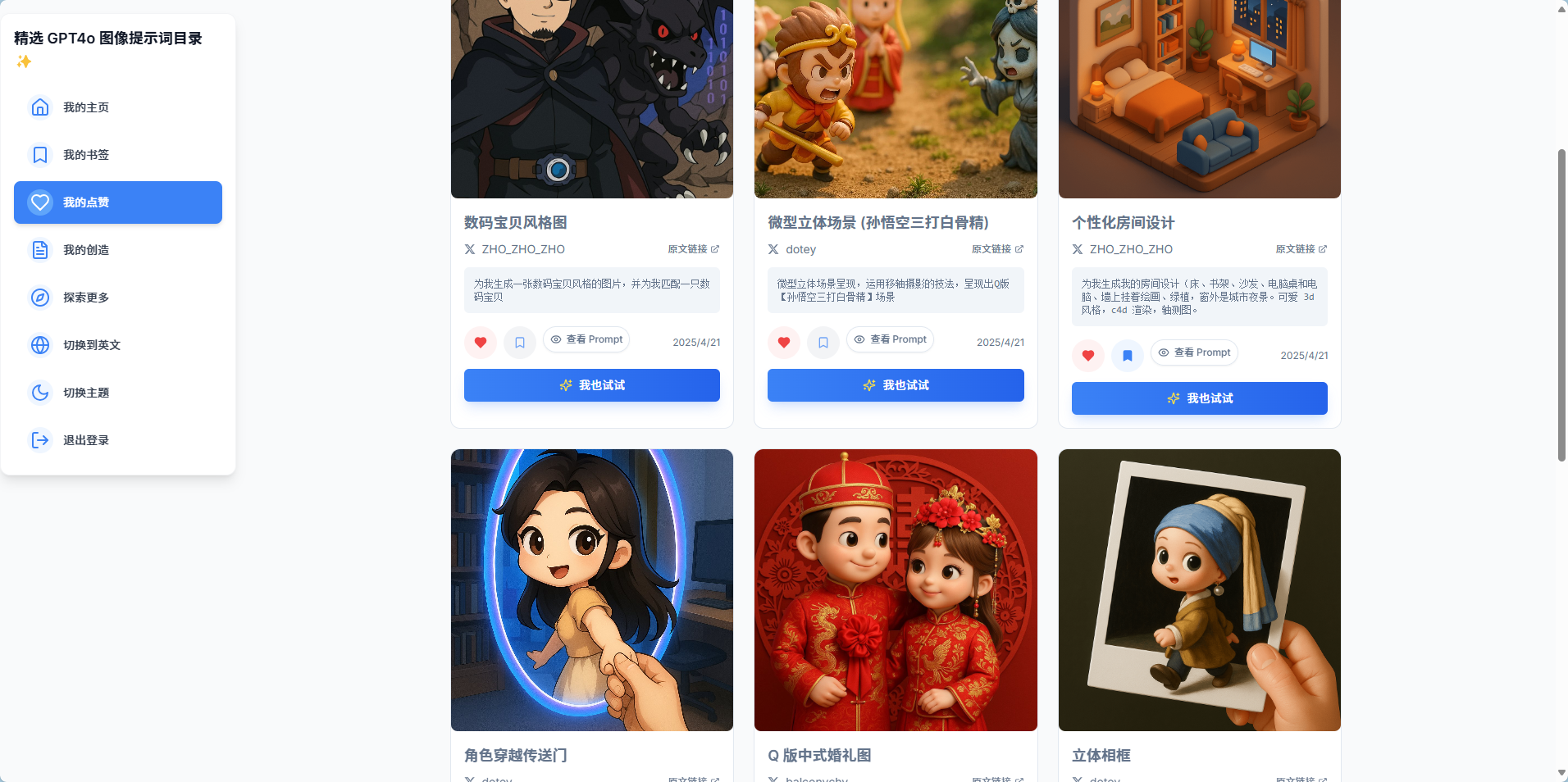
上线过程
上线过程就比较简单了,4月14日晚发布的第一版,相当于静态页面,所以当晚直接发布到Vercel上部署了,买个了域名awesome-gpt-images.com,添加到Vercel就发布了。
后来发现有些流量是来自国内,但是自己访问测试又很慢,所以改到Cloudflare Pages上发布了,通过全球CDN加速。由于不想备案域名,所以在Cloudflare上加了3级域名,在腾讯云加了3级域名的DNS解析与分流,国内流量分流至Cloudflare的优选地址,国外流量默认分流到Cloudflare全球CDN节点。最终看起来优选效果十分满意,国内180ms左右,国外当然更快。
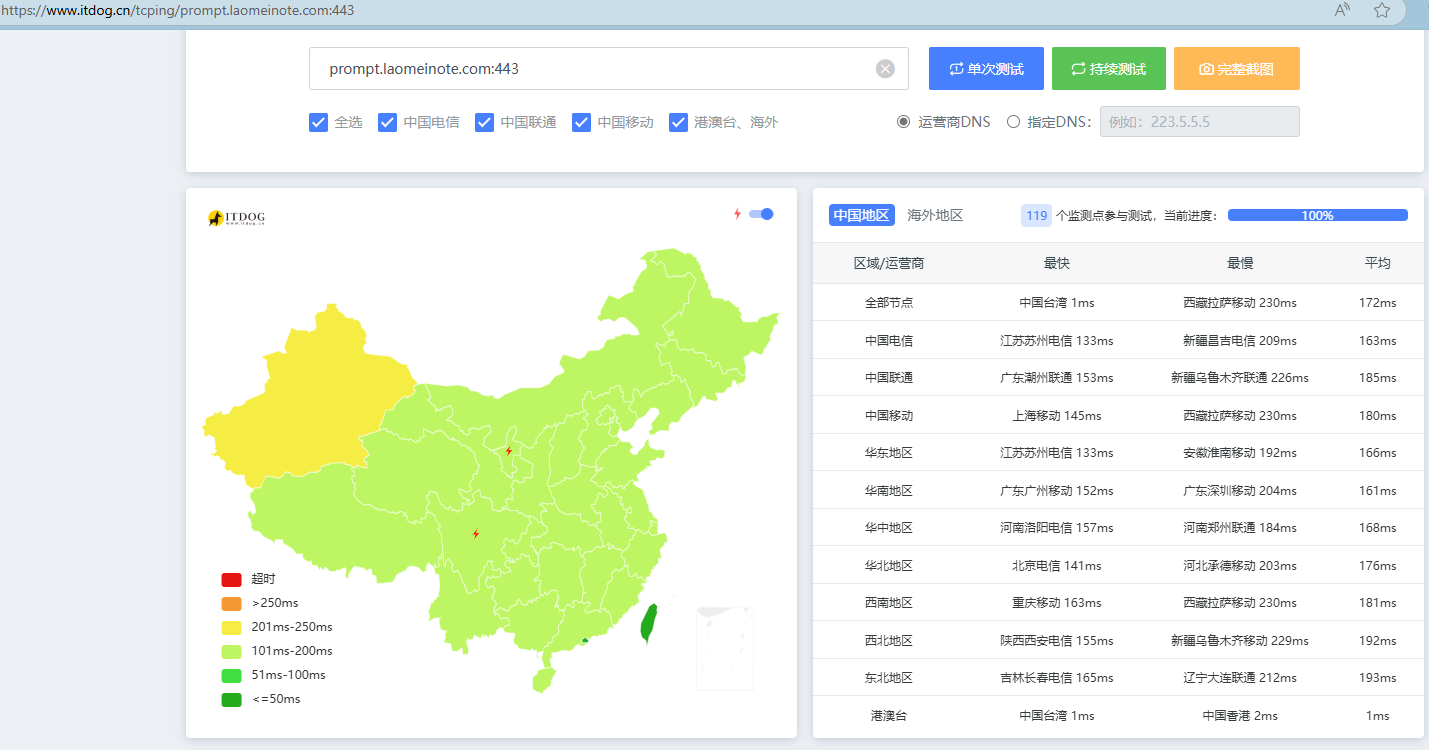
遇到的坑
中间还是遇到过一些坑,记录了一些。
坑1
部署到生产之后,使用google/github账号登陆,一直重定向localhost:3000本地地址中去,这是因为需要在Supabase中添加Redirect URLs:
- 登录 Supabase 控制台
- 进入 Authentication > URL Configuration
- 在 “Redirect URLs” 中添加:
https://prompt.laomeinote.com/auth/callback
之所以遇到这个坑,纯粹是自己不熟悉Nextjs与Supabase的Auth机制导致的,其实Windsurf也提醒过是这个原因,不过我一直没有处理好,结果Windsurf一直在查代码哪里有错误,最后切换回Cursor分析,Cursor查的原因也差不多,不过它的排除思路与解决方案很清晰,列出上述排除的步骤1/2/3, 解决方案一目了然,所以让我反过头去排除Supabase配置,而不是代码问题。从这点来看,Cursor排除问题与给解决方案还是更厉害一些,应该是Cursor的系统Prompt比Windsurf写的更好。
坑2
使用社交账号登陆的时候,Twitter一直登陆不成功,一直重定向到Supabase错误的地址,Cursor与Windsurf排查了很久,我都没发现问题,自己搜索谷歌,找到github上有人遇到类似问题,查看他们的issue提示需要注意:Twitter 开发者中填入到Supabase登陆账号需要使用API Key与API Key Secret,不是Auth Client ID和Auth Client Secret. (Google和Github都是这俩)。
解决问题后,反过头来看Cursor和Windsurf给的解决方案,才发现自己没有注意到它们的提示,Cursor已经提示过需要查API Key与API Key Secret,不过没有提不应该使用Auth Client ID和Auth Client Secret。
坑3
Twitter登陆的时候可以重定向到X了,但是登陆不成功,跟坑2是一样的,Cursor有所提示,自己没留意,查询Google才发现问题所在:
需要在Twitter开发者中APP需要设置,避免获取不到用户邮箱权限
Twitter 开发者平台配置:
- 在 “User authentication settings” 中:
- 确保勾选了 “Request email from users”
- Type of App 选择 “Web App, Automated App or Bot”
- Callback URL 设置为
https://xxxxx.supabase.co/auth/v1/callback, 即实际的Supabase中的回调URL
- 在 “App permissions” 中:
- 确保选择了 “Read” 权限
- 特别是要确保邮箱权限已启用
坑4
当 Supabase 发送验证邮件时,它使用配置的 Site URL 来构建验证链接,最终验证地址为localhost:3000的地址。终于吃一堑长一智,不再认为是代码问题,检查Cursor给的排除建议,登陆Supabase Dashboard修改配置后解决问题:
Supabase 配置检查:
在 Supabase Dashboard 中:
Authentication > URL Configuration:
- Site URL 应该设置为生产环境 URL:
https://prompt.laomeinote.com
- Site URL 应该设置为生产环境 URL:
Authentication > Email Templates:
- 确认邮件模板中的链接是否使用了正确的域名
经验总结
好了,大致过程总结完了,来个小结:
- Cursor/Windsurf目前使用的Claude 3.7对于写这类Nextjs项目基本没有问题,但是需要给出明确指示。不过感觉Cursor排查问题能力更强,应该是受益与系统Prompt写的好。
- 对于长文本数据处理,如果处理不好,可以借助Gemini 2.5 Pro处理,效果也很好。
- 对于Cursor/Windsurf处理不好的样式效果,可以借助V0写个原型,通过截图给Cursor/Windsurf。
- 迭代过程中每个功能完成后,或者问题解决后,尽快通过Git(git commit)打个结。
- 排除问题时,除了看AI修改代码以外,需要仔细分析对比它们的方案,参考上面的几个坑。
- 如果怕自己给的Prompt不合适,那就启用PLAN/ACT模式,让AI先出方案,明确告诉它你同意方案了再修改代码。
- 对于能使用文字描述说清楚的,最好不要截图,截图消耗更多credit。
- 对于存量项目,非常有必要把项目结构/具体的目录指定给AI,让它自己学习一遍,避免写冗余代码
上面是关于技术实践的总结,除此以外,还有两点小的思考:
- 自从去年尝试使用Cursor/Windsurf/Cline/Chatgpt/Claude/Gemini写APP以来,一直不太顺利,期间也废了两个OpenAI账号和两个Claude账号,虽然有些灰心,但是还是没有下船,还一直在船上,想到一句话,只要在船上就总有机会。当然,目前也没有实现多大成就,只不过完整的走了一遍Web App上线过程,而且比较轻松,算是一次祛魅过程,有了这次经验,下次应该就轻松多了。
- 关于需求的获取:需求来自哪里,这次我自己的需求是来自Twitter上少蒙同学在别人帖子下面发的评论,而大火的awesome-gpt4o-images仓库是来自资料整理,整理成目录。这类需求一直都在,还很强烈。
推荐
Online目录:https://prompt.laomeinote.com/
开源地址:awesome-gpt4o-images-prompt-online
欢迎Star,欢迎食用。
